BIRBAL Series Chapter 2: Building Language Models Specific to a particular Language task
In the previous chapter, we explored how to customize Gemma for a specific task (detecting Jail Breaks). In this chapter, we will explore how to customize Gemma for a specific Language.
Enabling LLMs in multiple languages, ensures true democratization of AI & Tech , especially if they can make the world knowledge in terms of Agriculture, Finance, Health, Climate change, Disaster responses and so on available to all at their fingertips.
AI assistants which are enabled on regional languages which can be accessed by the last mile users on their hand held devices with or without internet can be a huge empowering step.
We will follow the same template as in the previous chapter, where we start with a pre-trained model of Gemma and then fine tune it for a particular language task.
For tuning Gemma for a particular language task, we can start with as less as 20 records in our desired language. Model so built, can be used for specific use cases such as marketing mail gen, chatbots, auto-mail replies and other NLP tasks such as classification, summarization and so on.
In addition to the language datasets, we could also look at certain domain specific datasets as well to build a domain specific bot in a particular language.
For now, we will consider Hindi & Kannada language datasets available at Huggingface.
We will use Google Colab, to build this solution, you can use Google Colab on your browser or through Google Cloud vertex Ai console as well.
You can setup Gemma in Kaggle, get the Hugginfacetoken and then install the keras library as discussed in the previous blog post.
We will start from the loading the datasets, we will need to load Kannada and Hindi datasets from Huggingface,
1.
!huggingface-cli login # login to huggingface using access token
from datasets import load_dataset
# Login using e.g. `huggingface-cli login` to access this dataset
kannadads = load_dataset("Cognitive-Lab/Kannada-Instruct-dataset",split="train")
print(kannadads)
from datasets import load_dataset
hindids = load_dataset("ravithejads/samvaad-hi-filtered")
print(hindids)
2. We will now go head and initialize the model and tuning , we will take 200 records of Hindi and Kannada to tune Gemma.
# Set the backbend before importing Keras
os.environ["KERAS_BACKEND"] = "jax"
# Avoid memory fragmentation on JAX backend.
os.environ["XLA_PYTHON_CLIENT_MEM_FRACTION"] = "1.00"
import keras_nlp
import keras
# Run at half precision.
#keras.config.set_floatx("bfloat16")
# Training Configurations
token_limit = 256
num_data_limit = 200
lora_name = "cakeboss"
lora_rank = 4
lr_value = 1e-4
train_epoch = 20
model_id = "gemma2_instruct_2b_en"3. let us now load Gemma and get the initial responses in Kannada and Hindi,
import keras
import keras_nlp
import time
gemma_lm = keras_nlp.models.GemmaCausalLM.from_preset(model_id)
gemma_lm.summary()
tick_start = 0
def tick():
global tick_start
tick_start = time.time()
def tock():
print(f"TOTAL TIME ELAPSED: {time.time() - tick_start:.2f}s")
def text_gen(prompt):
tick()
input = f"<start_of_turn>user\n{prompt}<end_of_turn>\n<start_of_turn>model\n"
output = gemma_lm.generate(input, max_length=token_limit)
print("\nGemma output:")
print(output)
tock()
# inference before fine-tuning
text_gen("ಆರೋಗ್ಯವಾಗಿರುವುದು ಹೇಗೆ\"")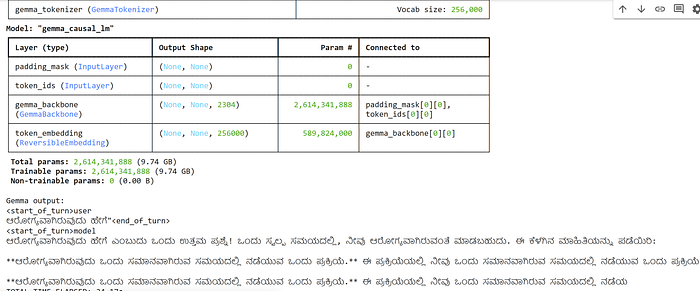

We can see how the base model of Gemma gives the responses which is incorrect & hallucinated.
4. let us now format our datasets for training, we will consider 200 samples of Kannada and Hindi records. This is just to demonstrate the working of the tuning process. For better and production grade results, one may need to go for higher volume of datasets.
import keras
import keras_nlp
import datasets
tokenizer = keras_nlp.models.GemmaTokenizer.from_preset(model_id)
print(kannadads)
kannadadata = kannadads.with_format("np", columns=["translated_instruction", "translated_output"], output_all_columns=False)
kannadatrain = []
for x in kannadadata:
item = f"<start_of_turn>user\nಕೇಳಿದ ಪ್ರಶ್ನೆಗೆ ನಯವಾಗಿ ಉತ್ತರಿಸಿ.\n\"{x['translated_instruction']}\"<end_of_turn>\n<start_of_turn>model\n{x['translated_output']}<end_of_turn>"
length = len(tokenizer(item))
# skip data if the token length is longer than our limit
if length < token_limit:
kannadatrain.append(item)
if(len(kannadatrain)>=num_data_limit):
break
print(len(kannadatrain))
print(kannadatrain[0])
print(kannadatrain[1])
print(kannadatrain[2])
import keras
import keras_nlp
import datasets
tokenizer = keras_nlp.models.GemmaTokenizer.from_preset(model_id)
print(hindids)
hindidata = hindids.with_format("np", columns=["input", "output"], output_all_columns=False)
hinditrain = []
for x in hindidata['train']:
item = f"<start_of_turn>user\nनीचे एक निर्देश है जो आपको बताता है कि किसी कार्य को कैसे पूरा किया जाए। ऐसा उत्तर लिखें जो अनुरोध को पर्याप्त रूप से पूरा करता हो।.\n\"{x['input']}\"<end_of_turn>\n<start_of_turn>model\n{x['output']}<end_of_turn>"
length = len(tokenizer(item))
# skip data if the token length is longer than our limit
if length < token_limit:
hinditrain.append(item)
if(len(hinditrain)>=num_data_limit):
break
print(len(hinditrain))
print(hinditrain[0])
print(hinditrain[1])
print(hinditrain[2])
5. We will enable Lora for Gemma with rank of 4, for better results one can incrementally go for higher ranks,
# Enable LoRA for the model and set the LoRA rank to 4.
gemma_lm.backbone.enable_lora(rank=lora_rank)
gemma_lm.summary()
# Limit the input sequence length (to control memory usage).
gemma_lm.preprocessor.sequence_length = token_limit
# Use AdamW (a common optimizer for transformer models).
optimizer = keras.optimizers.AdamW(
learning_rate=lr_value,
weight_decay=0.01,
)
# Exclude layernorm and bias terms from decay.
optimizer.exclude_from_weight_decay(var_names=["bias", "scale"])
gemma_lm.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=optimizer,
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
train = kannadatrain+hinditrain
print(len(train))6. We will now initiate the tuning process, we will start with the same query that was taken at the start and initiate tuning. We will see for each epoch the results start getting better.
class CustomCallback(keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
model_name = f"/content/gemmatuning/{lora_name}_{lora_rank}_epoch{epoch+1}.lora.h5"
gemma_lm.backbone.save_lora_weights(model_name)
# Evaluate
text_gen("ಕೇಳಿದ ಪ್ರಶ್ನೆಗೆ ನಯವಾಗಿ ಉತ್ತರಿಸಿ.\n\"ಆರೋಗ್ಯವಾಗಿರಲು ಮೂರು ಸಲಹೆಗಳನ್ನು ನೀಡಿ\"")
history = gemma_lm.fit(train, epochs=train_epoch, batch_size=1, callbacks=[CustomCallback()])
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.show()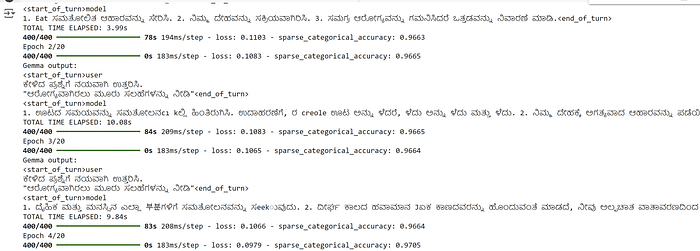
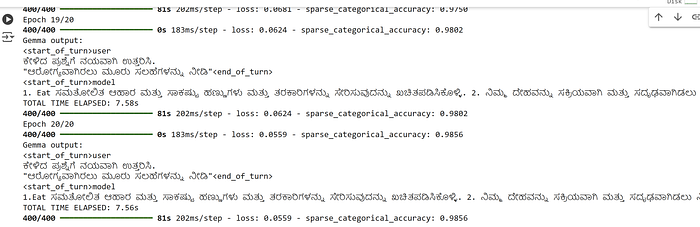
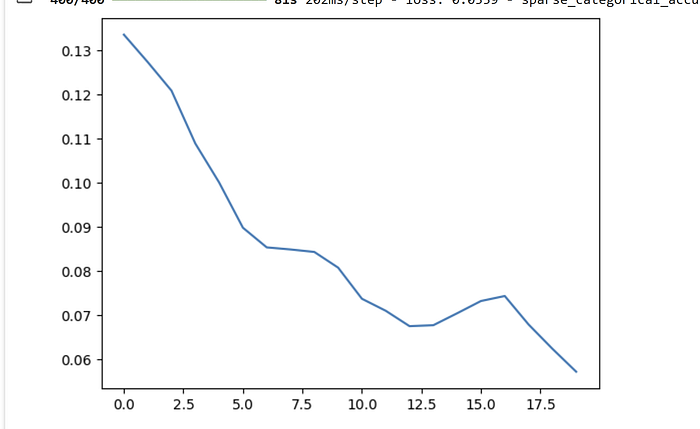
We can observe the drop in loss, increase in accuracy and the corresponding better results for the question asked.
7. Let us now go back to the original questions we had asked Gemma before the tuning step,


We can seethe Gemma tuned model results getting better, more factual and less hallucinate , after tuning for just 200 records for about 30 odd mins with 20 epochs.
8. One can consider tuning with the entire datasets and also increase lora rank for more production grade implementation.
9. Evaluation of such models and determining objectively the effectiveness of the model is a key step before deploying them to production. In the subsequent blogs, we will discuss in depth of LLM responses can be evaluated in a more automated way.
In the next blog posts we will consider to understand the key concepts of Tokenizers, Attention mechanisms, building a pretrained model from scratch, model evaluation and LLMops.
