Ravi ManjunathainGoogle Cloud - CommunityReimagining Data Engineering & Data Analytics with Gemini(views expressed are personal, they consist of point views and art of possible with Gen AI)8 min read·Mar 10, 2024----
Ravi ManjunathainGoogle Cloud - CommunityHow to Migrate BigQuery Datasets from one region to another?For customers in the FSI space, ensuring the Data residency clause is of utmost importance. This in turn requires migration of datasets…3 min read·Nov 2, 2023--1--1
Ravi ManjunathainGoogle Cloud - CommunityData Duets with BigQuery and Gen AI(views expressed are personal)4 min read·Oct 20, 2023--1--1
Ravi ManjunathainGoogle Cloud - CommunityCompetitor Analytics with Langchain Agents and Vertex Palm API“The best thing about Being Me …there’s so many ‘Me’s’ “is one of Agent Smith’s popular phrase from the Matrix Trilogy.3 min read·Jul 29, 2023--2--2
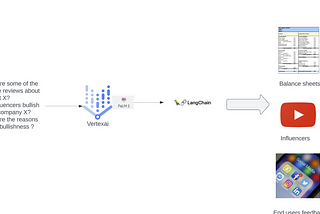
Ravi ManjunathainGoogle Cloud - CommunityInfluencer Analytics with Vertex AI PaLM APIs & Langchain(view expressed are personal, they do not represent that of organization’s)3 min read·Jul 9, 2023--1--1
Ravi ManjunathainGoogle Cloud - CommunityVideo AI to build your custom Tennis Video Library !AI in sports & fitness is an exciting prospect. Increasingly most professional clubs employ professionals who are adept at harnessing the…5 min read·Feb 10, 2023--1--1
Ravi ManjunathainGoogle Cloud - CommunityTales of BigQuery BenchmarkingDisclaimer: Views, thoughts, and opinions expressed in the blog belong solely to the author, and not necessarily to the author’s employer…8 min read·Jan 26, 2023----
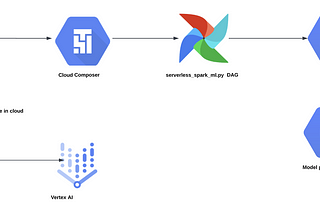
Ravi ManjunathainGoogle Cloud - CommunityServerless Spark ML pipeline in GCPIn the previous article on the Serverless Spark series we had described how a sample ETL pipeline can be developed. In this article, we…6 min read·Jun 26, 2022----
Ravi ManjunathainGoogle Cloud - CommunityServerless Spark ETL Pipeline Orchestrated by Airflow on GCPA Big Data Spark engineer spends on an average only 40% on actual data or ml pipeline development activity. Most of their time is often…5 min read·Jun 25, 2022--1--1
Ravi ManjunathainGoogle Cloud - CommunityMulti-Cloud Analytics with BigQuery Omni : No time to load !With increasing number of organizations adopting a Multi-Cloud Strategy, data movement has been a point of contention for the Analytics…7 min read·Mar 27, 2022--1--1